We tested five leading AI models: Claude 4.5, Perplexity Sonar Pro, GPT 5.1 Teams, Gemini 2.5 Pro, and Grok 4.1 – on identical digital marketing tasks to determine if they exhibit distinct writing styles.
The results confirm that, out of the box without training or directives, model personality is a measurable factor in results. Our analysis shows that Claude 4.5 excels at narrative and relationship-building, Perplexity Sonar dominates technical accuracy, and Grok 4.1 leads in local market engagement.
For content creators, this data suggests that success no longer comes from precise prompting alone, but from matching the specific “digital fingerprint” of an LLM model to the right type of job. We kept it simple, and hope there’s some value for you here.
What Lies Beneath…
I recently ran a test. I gave identical digital marketing instructions to five top-tier AI models.

I expected bland, soulless gruel. Instead, I got five distinct personalities.
Each model approached the same humdrum task like a different copywriter, with a different penchant, sitting at a conference table. Some were loud and punchy. Others were quiet and detailed. But each left a clear digital fingerprint.
For marketers building teams, this matters. If you don’t understand these differences, your brand voice risks sounding like a corporate handbook read by a robot. This simple analysis focuses on the edit distance – the gap between what the AI generated and what could actually be published on your “About” page.
Here is what happened when Claude 4.5, Perplexity (Sonar), GPT 5.1, Gemini 2.5 Pro, Grok 4.1, and that other one executed the exact same task.
The Best AI Tool for Marketing (Experiment)
The test and prompt were simple by design:
Create a 400 word description of Fast Frigate Digital Marketing. Index the site comprehensively to gain the knowledge you’ll need to do it properly: https://www.fastfrigate.com
Every model had the same prompt, comparable settings and access to the internet. The results proved that they “think” differently. Even the word counts told a story – Sonar stayed efficient at 320 words, while Gemini 2.5 Pro stretched to 450.
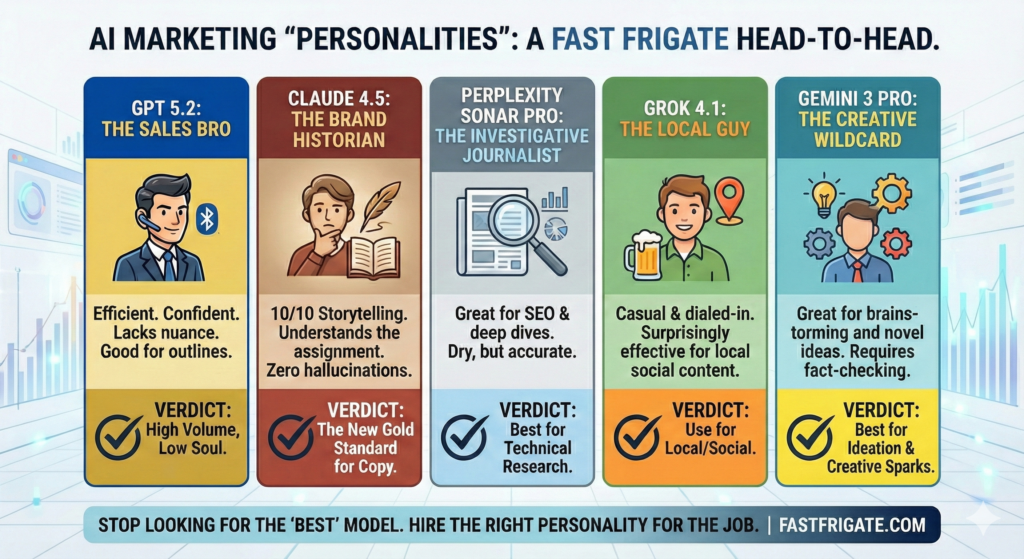
Meeting the LLM Contestants
Claude 4.5: The Thoughtful Consultant / Brand Historian
Claude positioned itself as a partner. It wove nautical metaphors (fitting for a “Frigate”) throughout the text and focused on long-term trust rather than quick wins. It had strong storytelling instincts. It made a joke. It had flair.
Perplexity: The Technical Analyst / Investigative Journalist
Perplexity skipped the fluff. It gave us bullet points and high technical detail. It nailed the facts – spotting our Burlington location and highlighting the Vermont market in the very first sentence. It sacrificed personality for precision. If you want just the facts, this is your model.
GPT 5.1: The Modern Executive / Sales Bro
GPT 5 came out swinging with a results-focused, modern pitch. It structured the text like a slide deck. It focused on 2025 trends and pulled specific client testimonials to build social proof. It used phrases like “without the bloat.” It felt like a CEO speaking to another CEO.
Gemini 2.5 Pro: The Corporate Academic / Confidently Wrong Intern
Gemini played the authority figure. It dug up the most background info – founding dates, team credentials, and executive names. It gathered facts better than anyone else, but the text was dense. The formal style works for big enterprise clients but might feel cold to a small local business.
Grok 4.1: The Local Guy / Over-Eager First Mate
Grok was the friendly neighbor who hasn’t returned your snowblower yet. . It mixed a conversational tone with deep local knowledge, talking about “tight-knit markets” and prevalence of tourism revenue in Vermont. It felt authentic and approachable, like a handshake rather than a contract. It may need to mind its manner sometimes, though.
Where Each Model Wins (and Fails)
We expanded the test to see how these personalities handled a few additional digital marketing tasks. We’ve decided to keep this LLM comparison to the company description task. Because results across the 4 AI tools was consistent (enough), and there are many additional, application agnostic, studies available for the intricate details. Here is our junior deckhand cheat sheet:
Claude 4.5
- Score: 10/10 for brand storytelling, copywriting, and almost anything client-facing.
- Accuracy: 10/10. It didn’t just browse; it surfaced older related articles like The Alligator Effect and Why Schema Markup Is Essential for AI Inclusion. That didn’t necessarily fit with the task, but I am always relieved when a result proves an LLM followed directions to the letter. Especially when it involves web browsing.
- Hallucinations: None.
- Robotic Phrases: “Eclipse competitors.” but that was likely it picking up on our site’s nautical theme.
- The Verdict: Winner. Claude captured the voice of Fast Frigate – nautical, slightly irreverent, and highly specific. It understood that we aren’t just an “agency,” but a partner for businesses that feel “adrift.”
- Time to Fix: 45 Seconds. (Mostly just trimming adjectives).
- The Catch: It likes to talk. Often over-explains things that should be simple. It writes like Stephen King, not Ernest Hemingway.

Perplexity
- Score: 9/10 for Technical SEO, research, and deep thinking. Gets deep into the weeds with masterful citations. With training and an uploaded Space file we’ve seen its authoring improve.
- Accuracy: 10/10.
- Hallucinations: None.
- Robotic Phrases: “Standout insights,” “tailored to Vermont’s competitive business landscape.”
- The Verdict: Useful for Research, less so for copy. It reads like a Wikipedia entry. Dry, factual, and completely devoid of soul. Use this to check facts or a draft outline, not to write your brand story.
- Time to Fix: 3 hours (You would have to rewrite the entire thing to add personality).
- The Catch: It lacks nuance and emotion. It can leave consumer audiences feeling nothing.
GPT 5.1
- Score: 8/10 for Efficiency. Confident, supportive, and ready to act as a closer. It writes like a LinkedIn influencer.
- Accuracy: 9/10. It correctly identified our specific clients (Syntheum AI, Fluency Inc.) and nailed the service list.
- Hallucinations: Some. It made alarmingly creative assumptions about our pricing model that wouldn’t make the cut. And it loves to pretend it can’t do things (like simply access and read a URL) when it clearly can – and just did a minute prior.
- Robotic Phrases: “Move the needle,” “without the bloat,” “friction.
- The Verdict: Runner Up. If you need sales copy for a landing page, this is your tool. It breaks text into scannable lines and focuses on benefits (“buyers find you, trust you”). However, it lacks the warmth and personality that Claude was emoting.
- Time to Fix: 1 minute (Tell it to tone down the pitch and regenerate, bro).
- The Catch: It can sound generic or impersonal if you don’t watch it closely. We’ve seen it hallucinate humorously.
Grok 4.1
- Score: 10/10 for Local. Use it for social media and regional campaigns. Although it saw our nautical branding and decided to cosplay as a 17th-century sea captain. T’was a bit much, matey.
- Accuracy: 7/10. It extracted location details and the copy was reasonable for some (but not all) marketing scenarios.
- Hallucinations: Low/Moderate. It mentioned specific guides for “tourism or retail” which were not in the source text. It likely inferred this based on the Vermont location, but technically it added details that weren’t there.
- Robotic Phrases: “dives into”, “landscape”, “boost”.
- The Verdict: The Local bro. Grok understands themes but lacks subtlety. The best at social media.
- Time to Fix: 5 minutes. We’d strip out 50% of the boat metaphors to make it readable for a modern C-level executive.
- The Catch: It can be too casual. It might lack the weight needed for professional managed services.
Gemini 2.5 Pro
- Score: 8/10 for Research. That overconfidently incorrect intern who nods during morning stand-ups but but didn’t actually listen to a word. And is possibly hungover.
- Accuracy: 6/10. This is where the “Google Ecosystem” failed. The walled garden thwarted them from the inside.
- Hallucinations: Frightful.
- Robotic Phrases: “Comprehensive,” “optimize resources,” “turbulent waters”.
- The Verdict: It tried too hard to “sound” like a marketing agency and ended up inventing services and price points we don’t offer. This is dangerous for a brand; if a potential client asks about something inferred online, and you say “we don’t do that,” you look disorganized. Potentially even dishonest.
- Time to Fix: Indefinite? (You may have to fact-check every single claim).
- The Catch: It risks information overload. It prioritizes being “complete” over being clear. Thought for a second I was talking to C-3PO or maybe… Twicky from Buck Rogers.
Build Your Stack, Don’t Pick a Winner
The smartest marketing teams aren’t looking for the “one true model.” They are building a bona fide LLM team.
They use Claude to write the brand story. They use Perplexity to write the technical docs. They use GPT to create the social media calendar, Gemini to research the competition, and Grok to write the Director of Marketing’s wedding speech.
Teams that match the model to the specific task report seeing measurable gains in efficiency compared to using a one-size-fits-all approach. And by “teams”, I mean… Fast Frigate.
AI Model for Task FAQ
Which AI model is best for copy/creative writing, voice, and branding?
Claude 4.5 rules the roost for storytelling and B2B communications. It uses focused language and metaphors intended to build trust, making it ideal for long-form content where tone matters more than raw data speed.
Does it matter which AI model I use if I give them the same prompt?
Yes. Our “Fast Frigate” experiment showed that even with identical instructions, word counts and focus areas vary wildly. For example, Perplexity produced a concise 320-word technical summary, while Gemini 2.5 Pro generated a detailed 450-word corporate history. The model you choose dictates the voice of the output.
Which AI tool is best for SEO and technical content?
Perplexity scored highest for SEO and technical writing (9/10). It loves bullet and numbered lists, metric confirmation through sources, and impressive accuracy. It won’t be a shoulder to cry on though – so look elsewhere for the emotional hook integral for consumer marketing. Claude will listen.
Is Grok good for business marketing?
Grok 4.1 is highly effective for local businesses and social media. It demonstrated a unique ability to understand regional markets (specifically Vermont in our test) and used casual, authentic language. It is great for “friendly neighbor” appeal but may be too informal for corporate enterprise contracts.
Should I stick to one AI model for all my content?
No. Build a bespoke “AI Stack” customized for your team, and diversify the models you’re using based on their strengths at specific marketing tasks. Forcing one model to do everything is a square peg in a round hole.
In Closing
Critics, chicken littles and nay-sayers worried AI would make all marketing sound the same. We found the opposite. We are seeing specialization and opportunity as long as pros and cons are understood.
It reminds me of vintage handwriting analysis. You can look at the loops and lines and tell who wrote the note. Or whether or not they’d just fallen off a unicycle. The same is now true for AI.
Your job isn’t just to prompt anymore. It is to cast the right character for the role. Match the digital voice to the challenge, and you won’t just get faster output – you’ll get better generations for marketing efficiency! And don’t get me wrong: I really love Grok, and I’m warming up to Gemini.
 How to Turn Old Articles into High-Performing SEO Assets
How to Turn Old Articles into High-Performing SEO Assets