Fast Frigate Digital Marketing explains why the deprecation of FAQ rich results in Google Search changes nothing about the value of FAQPage schema for Generative Engine Optimization (GEO). The May 2026 sunsetting removed the visual display of expandable Q&A boxes in traditional search results. It did not remove the ability of AI crawlers, ChatGPT, or Google’s Knowledge Graph to parse structured data. You should continue using FAQ schema – it remains one of the cleanest, most extractable signals for AI citation across every major generative platform.
What Lies Beneath…
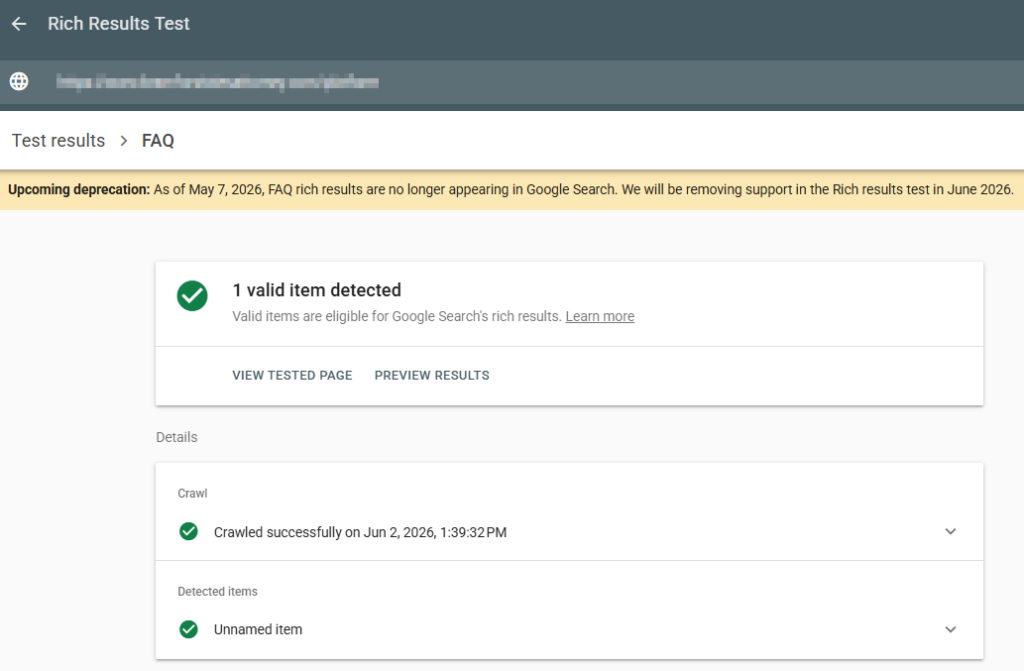
We were running a routine audit for a political campaign client when we saw it. A small, unceremonious banner appeared at the top of Google’s Rich Results Test tool around early May 2026. It read: “Upcoming deprecation: As of May 7, 2026, FAQ rich results are no longer appearing in Google Search. We will be removing support in the Rich Results Test in June 2026.“
We felt the usual spectrum of SEO emotions. Betrayed. Bewildered.
Fear, A brief moment of panic about client reporting. Then we looked closer at what Google was actually saying, and the panic evaporated. Most digital marketers will either rush to strip FAQ schema from their sites or ignore the update completely. Both reactions are wrong. Google killed the display layer. They did not touch the data layer. That distinction is exactly why FAQ schema is more valuable today for AI citation than it ever was for those expandable dropdown boxes.
Removing it would be like… piercing the toast.
The Display Layer Versus The Data Layer
Search engines operate on two distinct tracks. There is a data layer where they crawl, parse, and organize information into entities and relationships. There is a display layer where they decide how to render that information to a human user on a screen. For years, FAQ schema operated on both tracks simultaneously, and that dual function is what made it so attractive to marketers.
You added the JSON-LD code to your page. Google parsed the data layer, understood you were answering specific questions, and rewarded you on the display layer with massive, pixel-hogging rich results. Those rich results drove real click-through rate gains. Marketers noticed. They started stuffing FAQ schema onto every product page, category page, and blog post they could find, regardless of whether those pages actually contained genuine FAQs. Google responded the way Google always responds to aggressive scaling. They restricted the feature to government and health sites in August 2023, citing quality concerns about how the markup was being used. In May 2026, they shut it down entirely for everyone.
The rich result is gone. The underlying parsing mechanism is completely intact.
Google’s own documentation explicitly states that unused structured data does not cause problems for Search. FAQPage remains a fully valid Schema.org type. When Googlebot crawls your page, it still reads the JSON-LD. It still feeds that structured relationship into the Knowledge Graph. And every other crawler on the internet reads it too. PerplexityBot, ChatGPT-User, and Claude all parse the open web looking for clear, unambiguous answers to user queries. They do not care about Google’s display policies. They care about extraction efficiency.
The honest version of this story is that most sites never should have been using FAQ schema the way they were. Slapping it on a product page with three marketing-speak questions was never a legitimate use of the markup. The deprecation just made that obvious.
Why AI Engines Prefer Structured Questions
Generative Engine Optimization (GEO) requires a different mindset than traditional SEO. You are no longer trying to convince an algorithm to rank a blue link. You are trying to convince a Large Language Model (LLM) to extract your specific sentence and cite it as fact. Those are very different problems, and the solutions look different too.
AI models are literal parsers. They struggle with long, meandering paragraphs that bury the point. They excel at extracting modular, self-contained units of information. An FAQ block is the perfect structural match for an AI prompt. A user asks a question. The model looks for that exact question in its index. If your page features that precise question, followed immediately by a direct answer, the model has zero extraction friction. It lifts your answer and cites your domain. If your page buries the answer in the third paragraph of a 600-word section, the model may not find it at all, or worse, it finds a competitor’s cleaner version and cites that instead.
The numbers back this up. Industry analyses show that pages with schema markup are significantly more likely to appear in AI-generated citations. Fast Frigate’s own tracking data confirms that pages using structured data are up to 40 percent more likely to appear in AI summary positions. This is not a coincidence. It is a direct result of feeding machines the exact format they are trained to prefer. According to Ahrefs research, AI Overviews reduce clicks to websites by 34.5%, which means the citation itself – not the click – is increasingly where your brand’s visibility lives.
When you remove FAQ schema, you remove the machine-readable map of your content. You force the AI to guess which paragraph answers which question. AI engines do not like guessing. They prefer certainty. If a competitor provides that certainty through clean schema and structured on-page text, the competitor gets the citation. It really is that direct.
The Dual-Layer Citation Model
Understanding how AI citations actually work requires separating two pathways that most SEOs collapse into one. They assume ChatGPT reads the JSON-LD code directly and cites it. That is inaccurate. LLMs tokenize raw text. They do not semantically validate JSON-LD the way Google does. The citation process happens through a dual-layer model, and knowing which layer does what changes how you allocate your optimization effort.
The first layer is the indirect pathway through Google’s Knowledge Graph. Google crawls your FAQ schema. It uses that structured data to build entity relationships and establish topical authority. That authority improves your traditional organic ranking. A large percentage of Google AI Overviews citations are pulled directly from the top ten organic results, so stronger Knowledge Graph representation leads directly to higher AI Overview visibility. The schema does not get you cited by AI directly. It gets you ranked, and ranking gets you cited. That chain matters.
The second layer is the direct pathway through visible on-page content. Your FAQ schema must perfectly match the visible text on your page. When Perplexity or ChatGPT crawls that visible text, it tokenizes the question-and-answer format. The AI recognizes the structural pattern. It sees a 50-word, self-contained answer that directly resolves a user query. It extracts that visible text and cites it. The JSON-LD is not what gets extracted. The visible text is. But the JSON-LD tells the traditional index that the visible text is authoritative, which feeds back into Layer One.

The schema feeds the traditional index. The visible text feeds the LLM. You need both to win in 2026. Our article on schema for GEO breaks down the exact extraction patterns if you want to see how this plays out across specific schema types and platforms.
The correlation between schema and AI citation is not uniform across platforms. Perplexity shows a much stronger correlation with structured data than ChatGPT does. ChatGPT weights domain authority more heavily. So if your site has strong link equity, the visible content layer matters more than the schema layer for ChatGPT specifically. If you are building authority from scratch, the schema layer does more work. Neither approach is wrong. They are just different tools for different situations.
What You Should Do With Your Existing Schema
The worst thing you can do right now is assign a developer to strip FAQPage markup from your entire website. You will waste resources and actively harm your AI search visibility. There is no upside to removing valid, accurate schema.
Leave your existing, valid schema exactly where it is. If the markup accurately reflects the visible questions and answers on the page, it is still doing valuable work in the data layer. You only need to remove schema if it is orphaned. If you deleted an FAQ section from a page but left the JSON-LD in the header, you have a mismatch. Fix the mismatch. Otherwise, let the code run.
Your focus should shift entirely to the quality of the answers themselves. Schema cannot save a terrible answer. We see clients fail here constantly. They write 200-word rambling essays for a single FAQ entry. AI engines will not cite a 200-word essay. They want a 40-word capsule that leads with the conclusion, includes one grounding fact, and stops. Sometimes referred to as a “doorway paragraph“.
If you need a framework for structuring this type of content, our guide to optimizing for AI search citations covers the exact answer format that earns AI citations across ChatGPT, Perplexity, and Google AI Overviews.
There is a practical housekeeping item worth flagging for teams running automated reporting. Google is removing the FAQ rich result data from the Search Console API in August 2026. If your dashboards or BigQuery exports pull that data, those calls will return null after the August deadline. Pull the historical data you want to keep before then and update your reporting flows. It is a minor operational task, but the kind of thing that causes a silent failure in a dashboard three months from now if nobody addresses it.
Going forward, add FAQ schema to new pages whenever you publish genuine, high-quality FAQ sections. Not marketing questions. Not product features dressed up as questions. Real questions your audience actually asks, with real answers that resolve the query in the first sentence. That is the standard. It was always the standard. The deprecation just removed the cosmetic reward for ignoring it.

An FAQ on FAQ Schema?
What exactly did Google change about FAQ schema in May 2026?
Google stopped displaying FAQ rich results in standard search listings as of May 7, 2026. They removed the expandable question-and-answer dropdowns that used to appear under organic links. They did not penalize the use of the schema itself, and they continue to parse the structured data for indexing purposes. The Search Console FAQ report and Rich Results Test support are being removed in June 2026, and Search Console API support ends in August 2026.
Does AI read FAQ schema directly?
LLMs like ChatGPT tokenize all HTML text, including schema blocks, but they do not parse it as structured data the way Google does. The visible question-and-answer text on your page is what ChatGPT actually extracts and cites. The schema serves as a structural signal for traditional search indexes, which indirectly supports your overall authority and ranking – and ranking feeds AI Overview citation probability.
Should we stop adding new FAQ schema to pages?
No. You should continue adding FAQ schema whenever you publish a genuine, high-quality FAQ section. It remains a sound practice for structuring data for machine readability. The purpose has shifted from chasing a visual SERP feature to building entity authority and supporting AI extraction, but the underlying value is intact.
How long should an FAQ answer be for the best AI citation chances?
Keep your answers between 40 and 60 words. AI engines prefer concise, self-contained units of information. Lead with a direct answer in the very first sentence. Do not bury the response under marketing language or unnecessary context. One supporting fact or statistic per answer is ideal.
Is FAQ schema still relevant for SEO in 2026?
Yes, though the reason has changed. FAQ schema is no longer a lever for visual SERP features. It is a signal for entity authority in Google’s Knowledge Graph and a structural aid for AI extraction. For GEO strategy, it remains one of the highest-value schema types available.
The New Rules Of FAQ Engagement
The deprecation of FAQ rich results is a perfect example of why chasing visual SERP features is a losing game. Google owns the display layer. They will always reclaim visual real estate when it suits their product goals. You cannot build a long-term strategy on rented pixels.
You build a long-term strategy on the data layer. Structuring your content clearly, answering real user questions directly, and making your expertise machine-readable will never go out of style. AI search engines are desperate for clean, authoritative, extractable facts. FAQ schema combined with sharp, concise on-page writing provides exactly that. Stop worrying about the dropdown boxes you lost. Start optimizing for the AI citations you can win.
Just don’t pierce the toast, folks. We’re going to be just fine.
 How to Track AI Search Visibility: A 7-Step B2B Framework
How to Track AI Search Visibility: A 7-Step B2B Framework